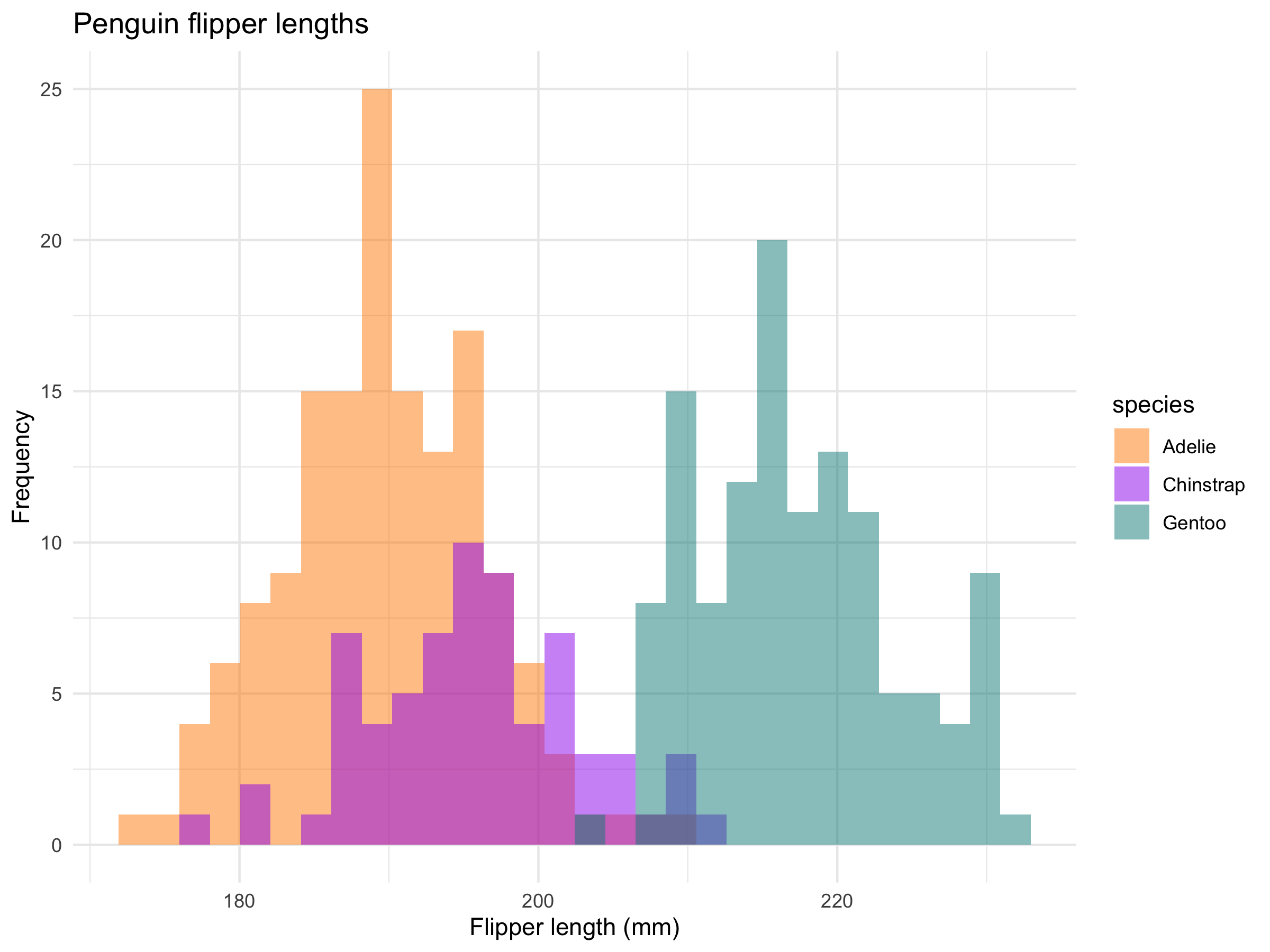
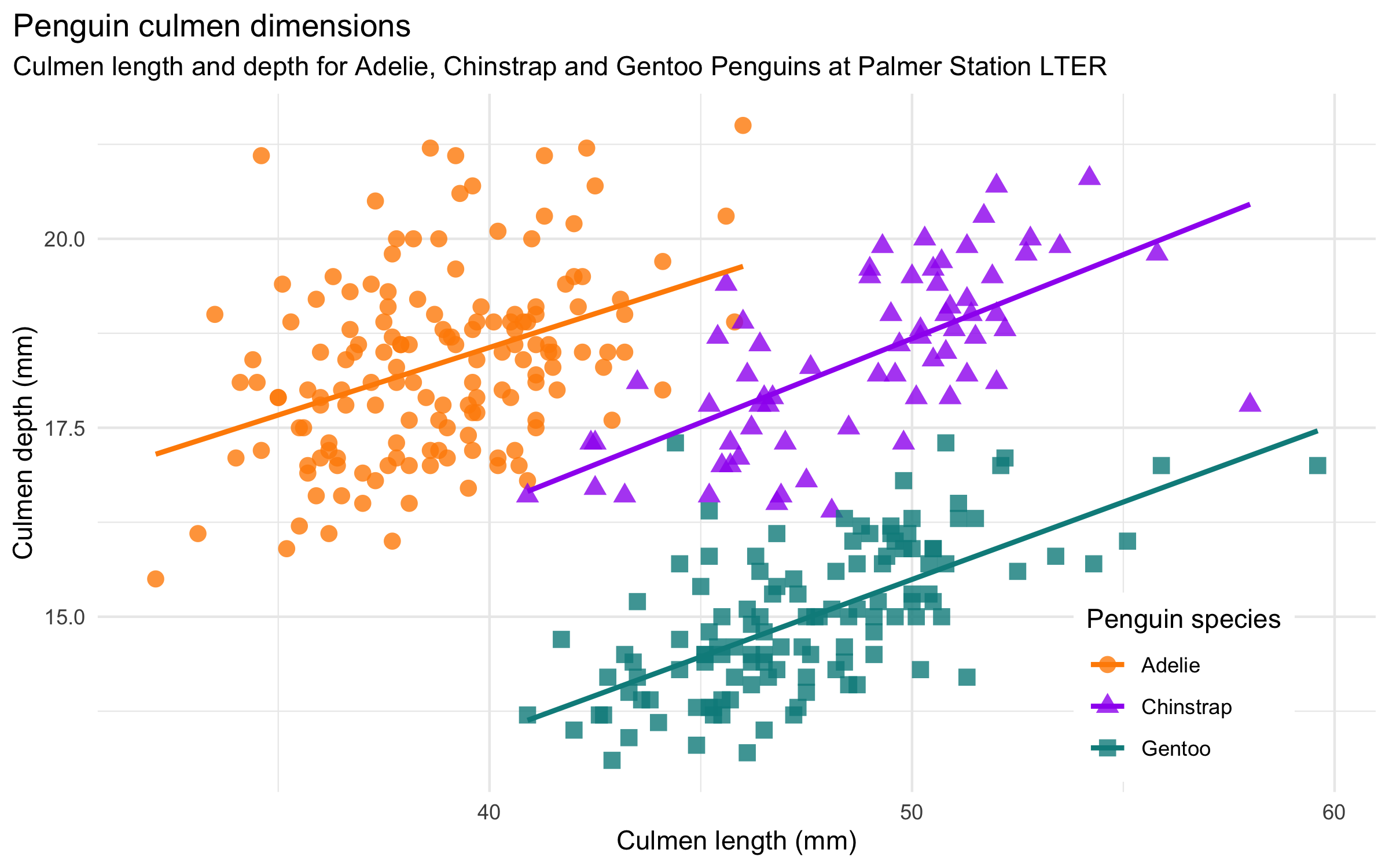
The discipline of data science is notoriously difficult to define, and yet it is perhaps not impossible. I am currently working to gear more of my thought and instruction around Stanford statistician David Donoho’s definition of Greater Data Science (GDS). Here I’ll provide a brief summary of three key contributions of Donoho’s argument, ending with his six-part definition of the discipline.
First, Donoho appropriately connects the current expansive discipline of Data Science to its roots in 50+ years of work by statisticians, beginning with John Tukey in the 1960s. On Donoho’s telling, contemporary Data Science should understand itself not in opposition to the discipline of statistics but as an outgrowth and extension of the long tradition of statistics. More than historical recognition, this extends to appreciating the contemporary relevance of both traditional statistical analysis and predictive modeling with machine learning. Just as traditional statisticians must acknowledge and embrace the importance and relevance of contemporary machine learning methods, “cutting edge” data scientists must appropriately recognize the continued role and relevance of traditional statistical analysis.
Second, Donoho helpfully identifies the Common Task Framework methodology that undergirds the successes of contemporary predictive modeling. This methodology includes (a) a publicly available training dataset, (b) a competitive multi-party approach to predictive modeling, and (c) a scoring referee or system for evaluating the competing models against a test dataset unavailable to the competitors. He cites the Netflix Challenge as a famous example of this approach.
Third, and most importantly, Donoho builds on the work of John Chambers and Bill Cleveland to outline a definition of Greater Data Science (GDS), which includes the following six sub-fields:
- Data Exploration and Preparation
- Data Representation and Transformation
- Computing with Data
- Data Modeling
- Data Visualization and Presentation
- Science about Data Science
This definition is so apt that it seems common sense to those who practice in the field. But the complexity of the work involved in data science has meant that reaching the clarity offered by this definition has not been easy. Not content simply to define, Donoho devotes the remainder of his piece to discussing and illustrating some of the key practices included under each sub-field. I will number each sub-field as he does, using GDS for Greater Data Science.
GDS1: Data Exploration and Preparation. Frequently requiring upwards of 80% of the work involved in data science, this sub-field is too often neglected in the teaching of data science and merits greater attention in the future. It includes the many steps of curating data, dealing with anomalies, and pulling into the shape needed for analysis.
GDS2: Data Representation and Transformation. This includes the problem of data storage and requires that a data science be fluent in current database technologies. As of 2021 that includes SQL and NoSQL databases, distributed (cloud) systems, etc.
GDS3: Computing with Data. This includes necessary knowledge of languages like Python or R and related current software used in preparation, analysis, and modeling, as well as understanding of the workflows used to in the development of an analytical process.
GDS4: Data Visualization and Presentation. This sub-field addresses the importance of visual analysis methods, from standard plots used in Exploratory Data Analysis (EDA) to advanced charts used to crystalize understanding of specific important features to interactive data dashboards.
GDS5: Data Modeling. This sub-field should rightfully include both traditional statistical approaches and contemporary predictive modeling with machine learning.
GDS6: Science about Data Science. Key to making data science a true science, science of data science investigates the real-world work of data scientists “in the wild” and contributes to the documentation, description, analysis, and evaluation of those real-world practices, with the express aim of discerning the more fruitful practices that show merit for leading the discipline of data science forward to greater promise and productivity.
Given the sheer complexity of data science and the astounding speed of its ongoing development, it is difficult to overstate the value of Donoho’s six-part definition of the discipline. For myself, I will be contemplating and engaging the implications of this definition for months and years to come.
Allow me simply to recommend Donoho’s article as a read of incredible value, and recommend his helpful discussions of these six sub-fields as a beginning point for others as we work together to take the discipline forward.
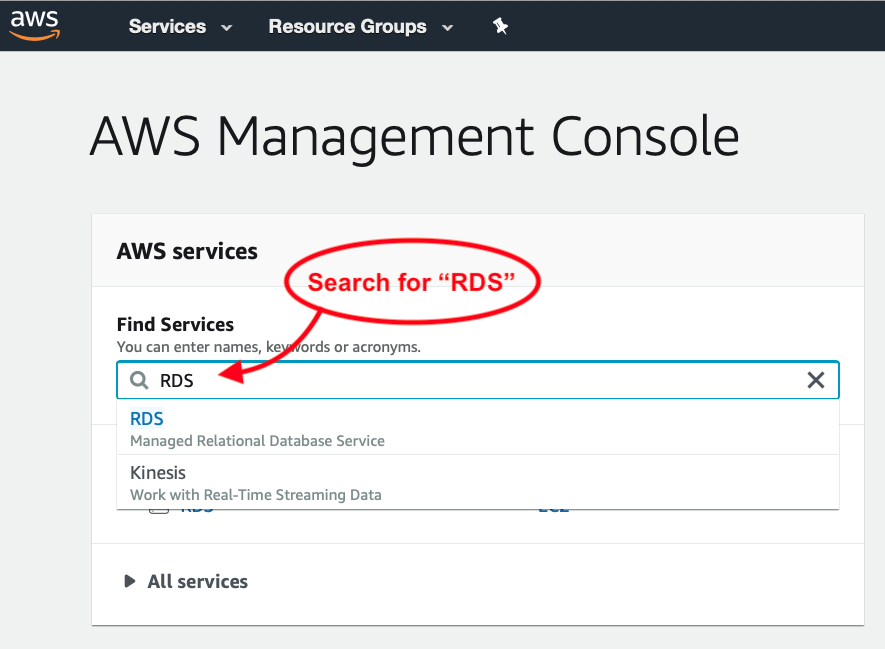

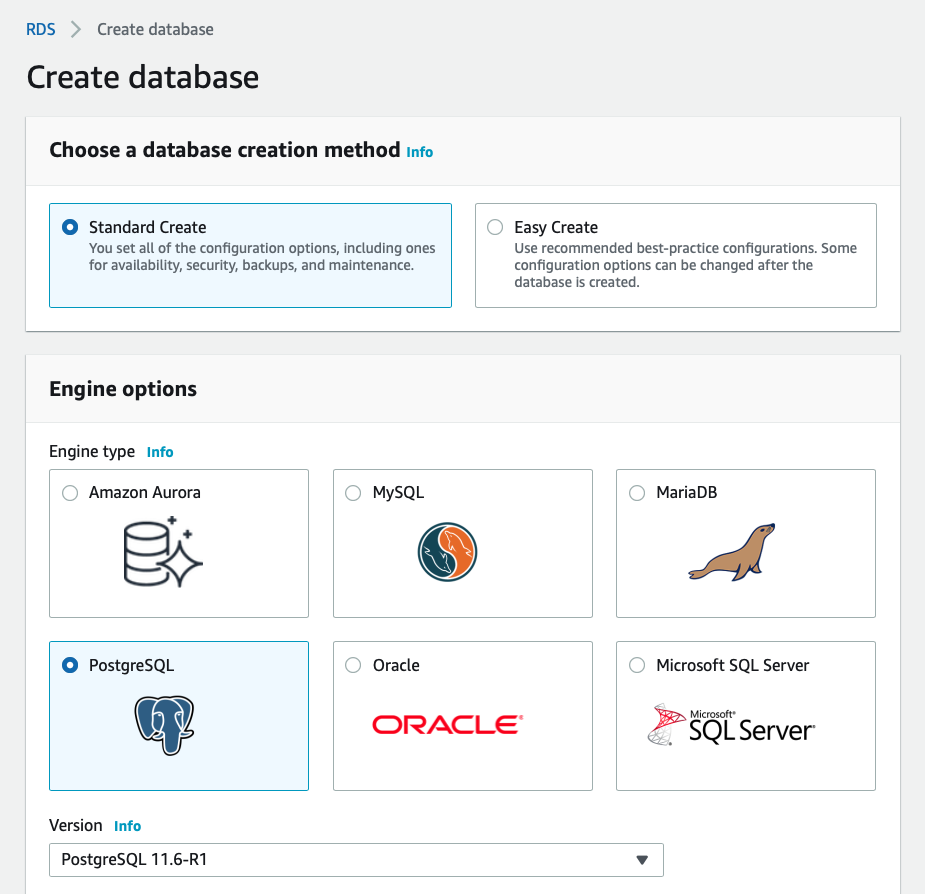

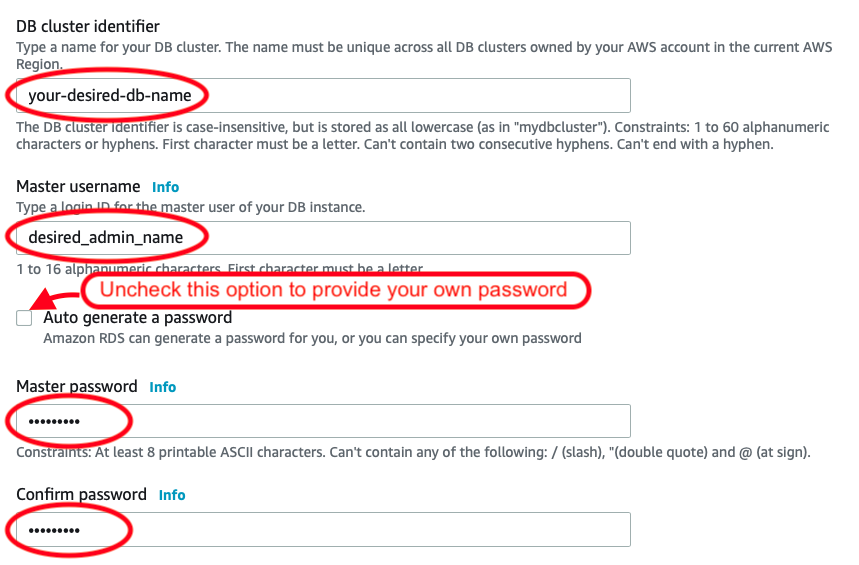
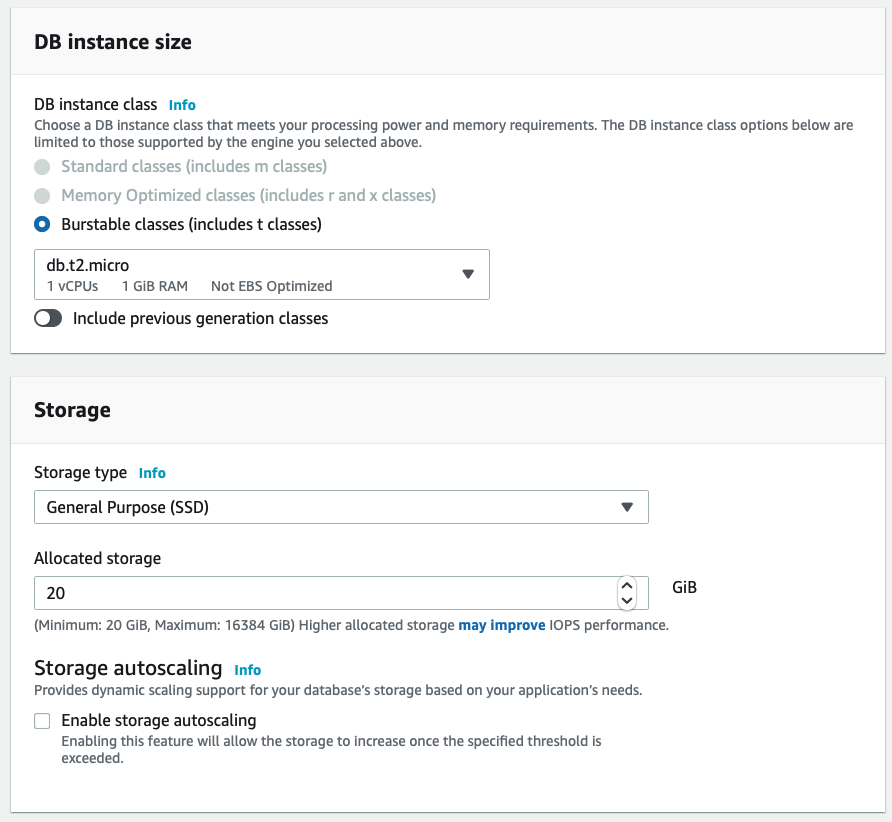
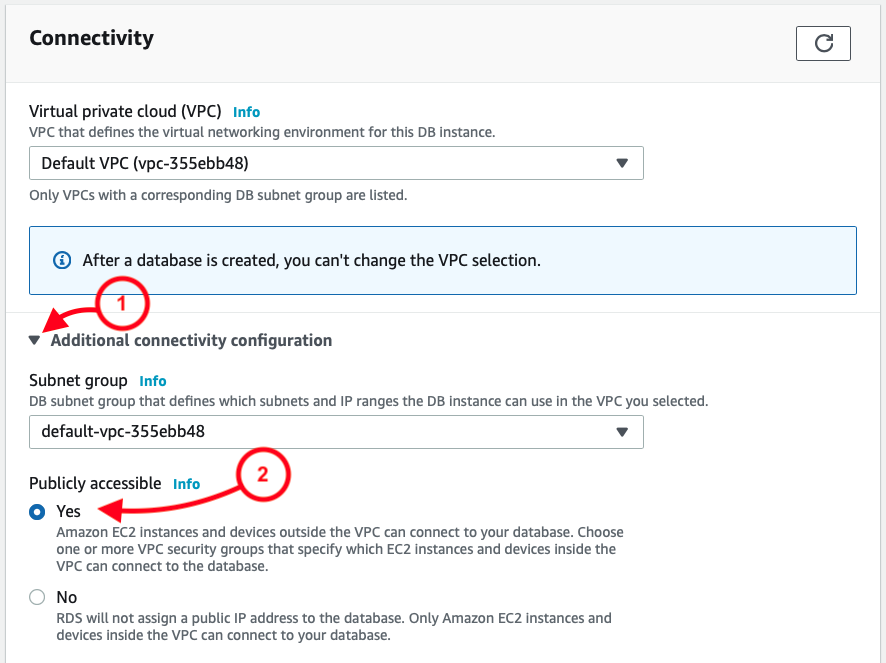
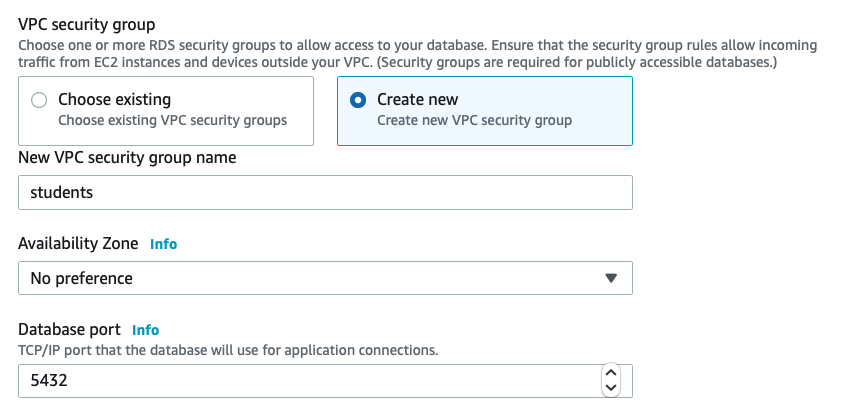

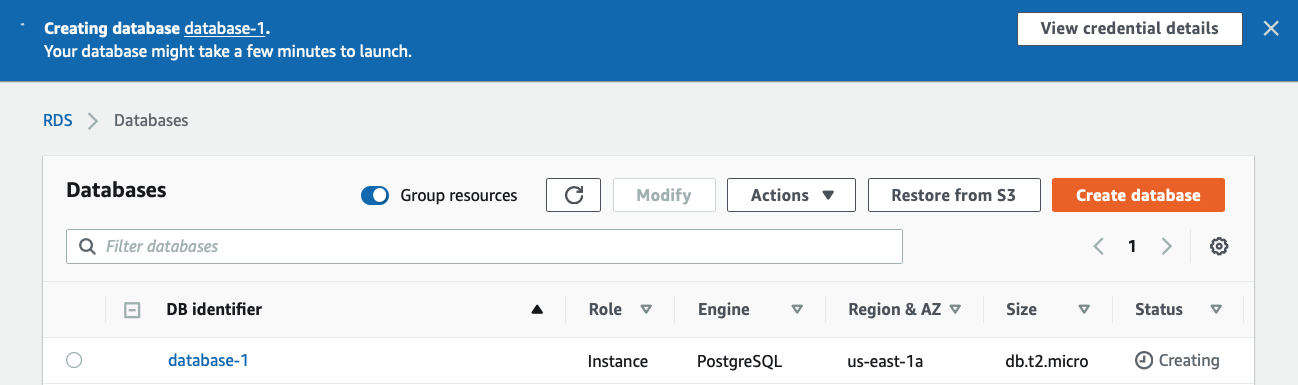
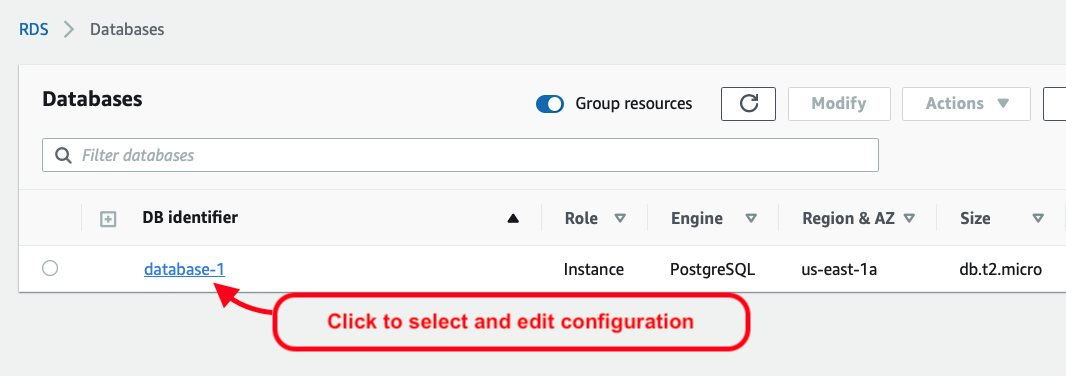
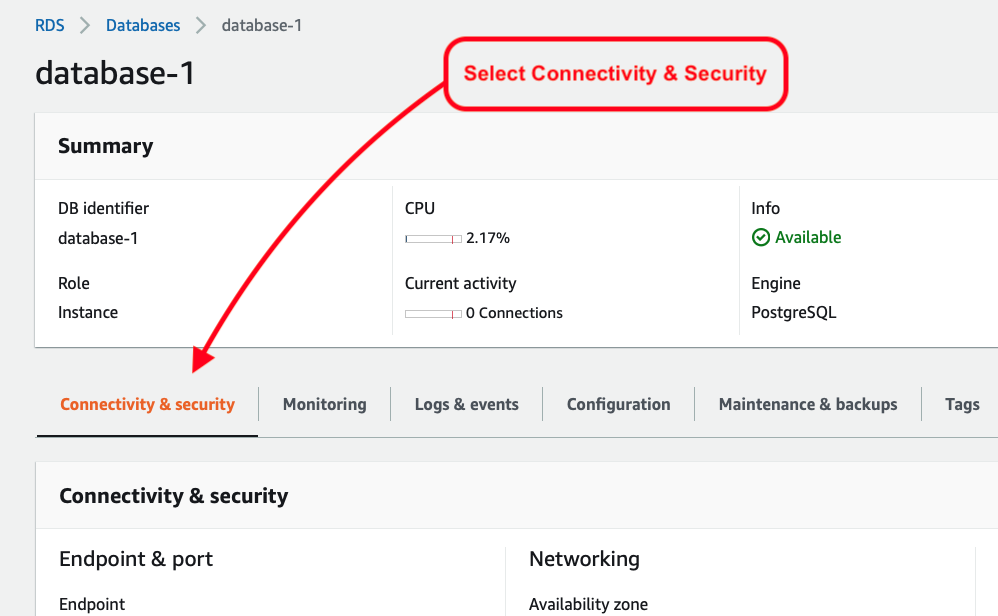
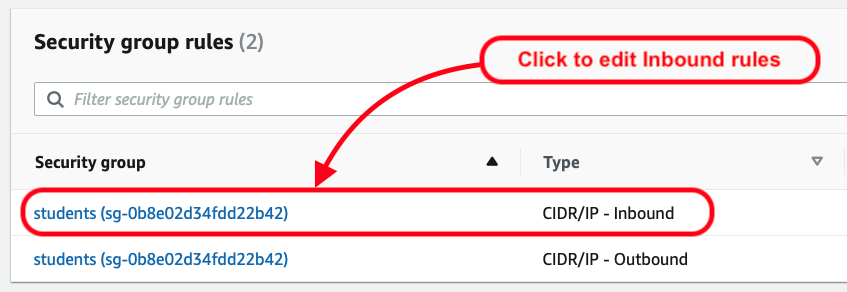
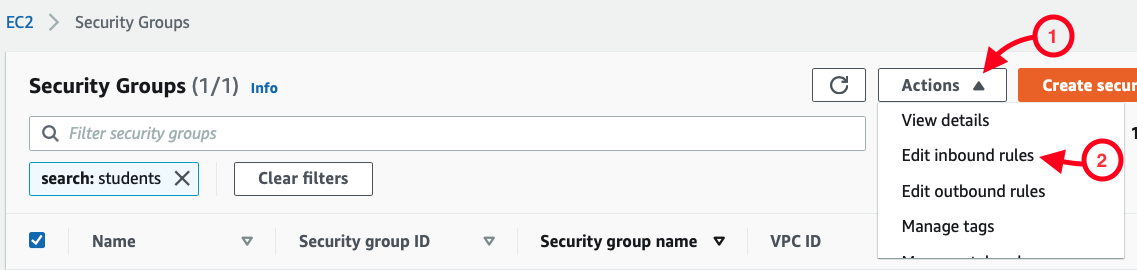
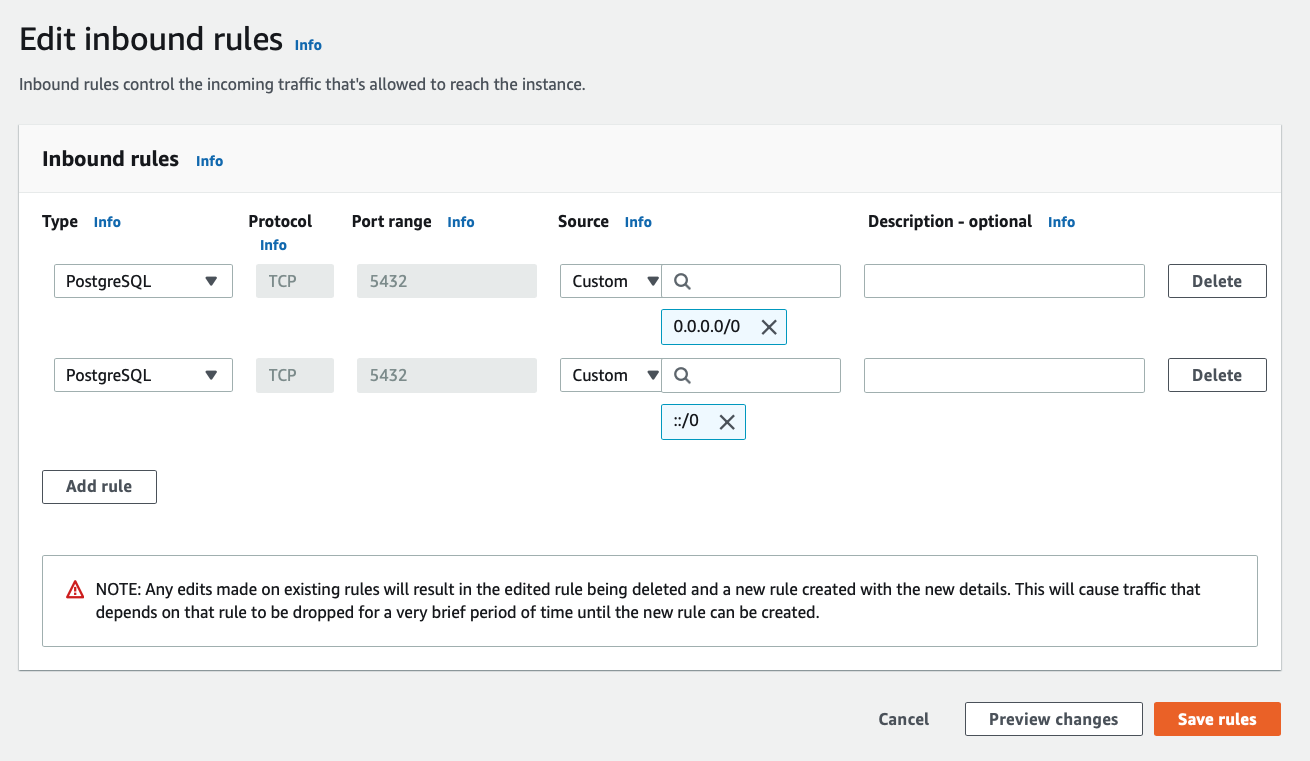
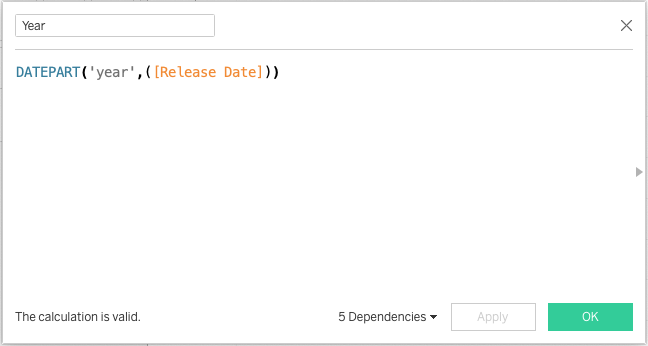
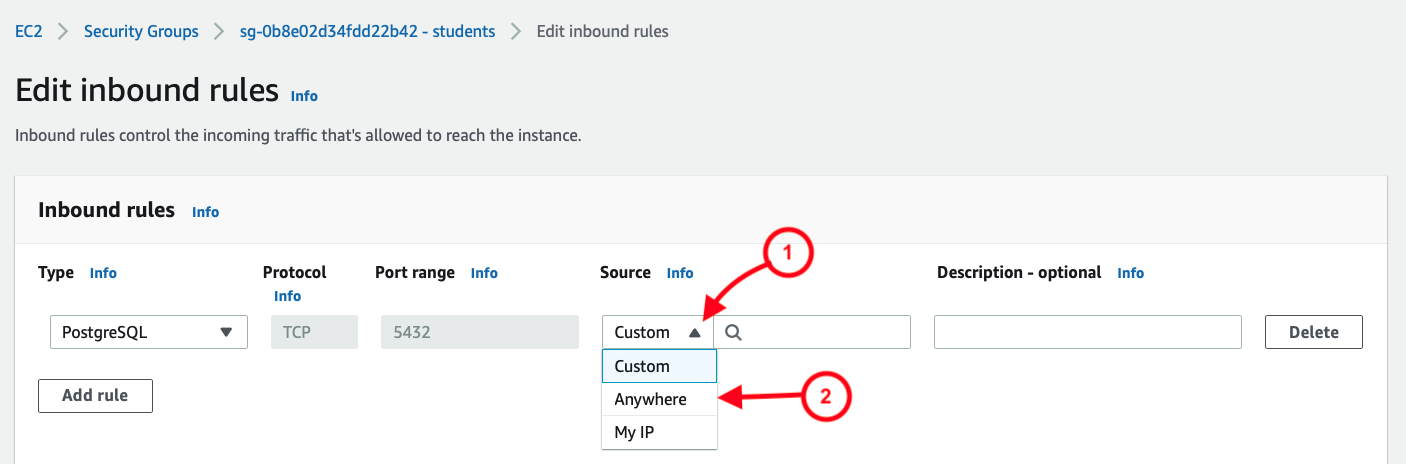 Once that’s been selected, I then see the result as two rules, allowing a full range of IP address options:
Once that’s been selected, I then see the result as two rules, allowing a full range of IP address options: